SelfSupervised-ViT-Noisy-Voice-Spectrograms
Self-Supervised Learning with Vision Transformer (ViT) for Noisy Real-World Voice Data
This repository contains the implementation of a self-supervised pretraining + supervised fine-tuning pipeline for classifying psychologically stable vs psychologically unstable voice samples under noisy real-world conditions.
The workflow first learns representations from unlabeled spectrograms using masked spectrogram reconstruction (self-supervised learning), then transfers the learned knowledge into a ViT-style Transformer classifier trained and evaluated on unprocessed / noisy voice data.
📄 Research Paper
Title: Self-Supervised Learning with Vision Transformer (ViT) for Noisy Real-World Data
Authors: Rafiul Islam, Dr. Md. Taimur Ahad, et al.
Status: Ongoing Research / Manuscript in Preparation
Note: The final paper link will be added here after submission/acceptance.
📊 Project Overview
Real-world voice data collected outside laboratory conditions is often noisy, untrimmed, and distribution-shifted, which significantly degrades the performance of fully supervised models trained on curated datasets. This project addresses this challenge by introducing a self-supervised representation learning stage prior to supervised classification.
The proposed framework consists of two stages:
- Self-Supervised Pretraining on unlabeled voice spectrograms using a masked reconstruction objective.
- Supervised Fine-tuning of a Vision Transformer (ViT)-style classifier on noisy / unprocessed data.
🔑 Key Highlights
- Input Representation: Log-mel spectrograms extracted from raw voice segments.
- Self-Supervised Objective: Masked spectrogram reconstruction using Mean Squared Error (MSE).
- Architecture: Frequency-aware CNN + Transformer blocks (ViT-style).
- Transfer Learning: Pretrained SSL weights transferred to the classifier.
- Evaluation Strategy: 5-Fold Cross-Validation + Ensemble of top-performing folds.
- Target Scenario: Robust classification under real-world noisy conditions.
- Ethics: Dataset is not included due to privacy and ethical constraints.
🧠 Methodology
1) Self-Supervised Pretraining (Masked Reconstruction)
- Combines all available processed spectrogram segments without labels.
- Randomly masks time–frequency regions in the spectrogram.
- Trains a reconstruction network to recover the original spectrogram.
- Loss function: Mean Squared Error (MSE).
- Learned weights are saved and reused for downstream classification.
2) Supervised Classification Model (ViT-style)
The classifier integrates multiple components:
- Frequency Band Attention to learn importance weights across frequency regions.
- Conv1D blocks for local temporal feature extraction.
- Transformer blocks (Multi-Head Self-Attention + Feed-Forward Networks) to capture global dependencies.
- Softmax output layer for binary classification.
3) Transfer Learning (SSL → Classifier)
- Loads pretrained weights from the self-supervised reconstruction model.
- Transfers compatible layers into the supervised classifier.
- Fine-tunes the model on unprocessed / noisy spectrograms.
📋 Requirements
- Python 3.8 or above
- TensorFlow / Keras
- Librosa
- NumPy, Pandas, Matplotlib, Seaborn
- Scikit-learn
- Imbalanced-learn (SMOTE)
- OpenCV, scikit-image
- visualkeras (for architecture visualization)
🛠 How to Run
1) Install Dependencies
pip install librosa matplotlib numpy pandas seaborn tensorflow keras scikit-learn tqdm imbalanced-learn visualkeras opencv-python scikit-image
2) Prepare Dataset
Create the following folder structure:
data/
├── processed/
│ ├── mentally_stable/
│ └── mentally_unstable/
└── unprocessed_noisy/
├── mentally_stable/
└── mentally_unstable/
Recommended audio and feature settings (from experiments):
- Sample Rate: 48,000 Hz
- Segment Length: 2 seconds
- Feature Type: Log-mel spectrogram
⚠️ The dataset is not included in this repository due to ethical and privacy considerations.
3) Run Notebook
Open and execute:
notebooks/Self_Supervised_Noise.ipynb
📊 Results
✅ Model Architecture
High-level visualization of the reconstruction and classification backbone:

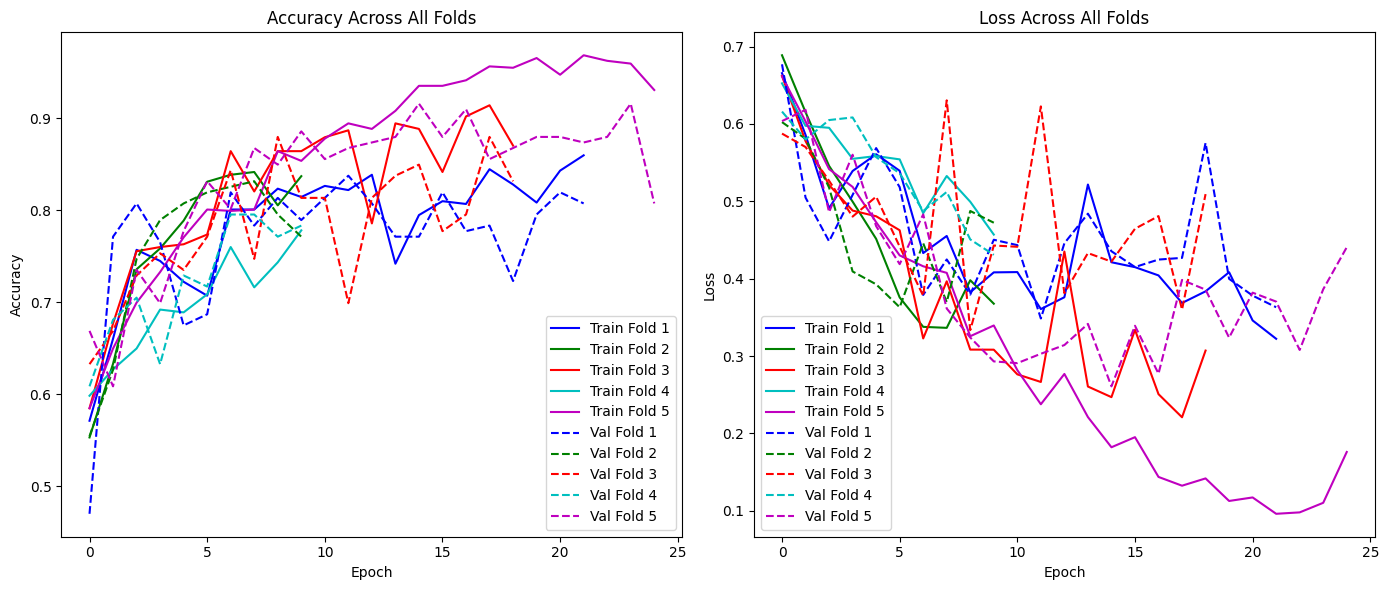
✅ 5-Fold Cross-Validation (Training Dynamics)
Accuracy and loss curves across all folds demonstrate stable convergence under noisy conditions:
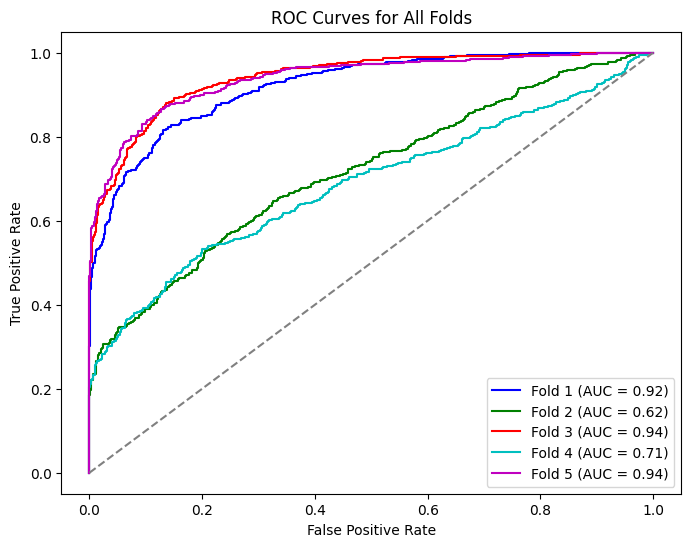
✅ ROC Curves Across All Folds
Receiver Operating Characteristic (ROC) curves for each fold indicate robustness and variability under distribution shift:
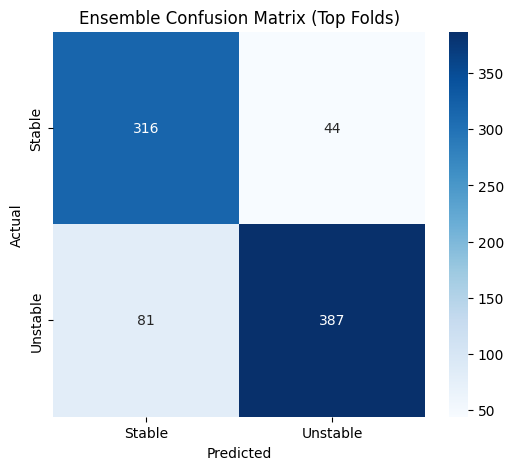
✅ Ensemble Confusion Matrix (Top Folds)
An ensemble of top-performing folds is used for final evaluation on the test set:
- Stable → Stable: 316
- Stable → Unstable: 44
- Unstable → Stable: 81
- Unstable → Unstable: 387
Overall ensemble performance:
- Accuracy: 84.90%
- Precision (Unstable as positive): 89.79%
- Recall: 82.69%
- F1-score: 86.10%
📜 Citation
If you use this work, please cite this repository (until the paper is published):
- Islam, R., Ahad, M. T., et al. (2026). Self-Supervised Learning with Vision Transformer for Noisy Real-World Voice-Based Psychological Stability Classification. GitHub Repository.
🧑💻 Author
- Rafiul Islam
-
Researcher Machine Learning & AI Engineer - Daffodil International University (CSE)
- Machine Learning Engineer @ Bondstein Technologies Ltd.
⚠️ Disclaimer
This project is for research and educational purposes only and does not provide medical advice or clinical diagnosis. Always consult qualified professionals for mental health-related decisions.